Un macrón (del griego μακρός makros "largo") es el diacrítico ¯ situado sobre una vocal para indicar que la vocal es larga. Tiene un significado opuesto al breve ˘, usado para indicar una vocal corta. Estas distinciones son usualmente fonémicas.
A macron, from the Greekμακρόv (makrón), meaning "long", is a diacritic placed above a vowel (and, more rarely, under or above a consonant). It was originally used to mark a long syllable in Græco-Roman metrics, but now also indicates that the vowel is long. (This is the opposite of a breve ˘, used to indicate originally a short syllable and now also a short vowel.) Distinctions between long and short vowels are often phonemic. In the International Phonetic Alphabet the macron is used to indicate mid tone; the sign for a long vowel is a modified triangular colon.
In Græco-Roman metrics and in the description of the metrics of other literatures, the macron was introduced and is still widely used to mark a long (i.e., heavy) syllable. Even the best and relatively recent classical Greek and Latin dictionaries[1] are still only concerned with indicating the length (i.e., weight) of syllables; that is why most still do not indicate the length of vowels in syllables that are otherwise metrically determined. Though many textbooks about ancient Rome and Greece employ the macron, it was not actually used at that time.
Transcriptions of Arabic typically use macrons to indicate long vowels — ا (alif when pronounced as /aː/), و (waw, when pronounced as /uː/), and ي (ya', when pronounced as /iː/). Thus the Arabic word ثلاثة (three) is transliterated ṯalāṯah.
Some modern dictionaries of classical Greek and Latin, where the macron is sometimes used in conjunction with the breve. However, many such dictionaries still have ambiguities in their treatment and distinction of long vowels or heavy syllables.
The Hepburn romanization system of Japanese. Examples: kōtsū (交通) "traffic" as opposed to kotsu (骨) "bone" or "knack" (fig.)
Latvian. "Ā", "ē", "ī", "ū" are separate letters that sort in alphabetical order immediately after "a", "e", "i", "u" respectively. Ō was also used in Latvian, but it was discarded as of 1957.
Lithuanian. "Ū" is a separate letter but given the same position in collation as the unaccented "u". It marks a long vowel; other long vowels are indicated with an ogonek (which used to indicate nasalization, but no longer does): "ą", "ę", "į", "ų", "o" being always long in Lithuanian except for some recent loanwords. For the long counterpart of "i", "y" is used.
Transcriptions of Nahuatl (spoken in Mexico). Since Nahuatl (Nāhuatl) (Aztecs' language) did not have a writing system, when Spanish conquistadors arrived, they wrote the language in their own alphabet without distinguishing long vowels. Over a century later, in 1645, Horacio Carochi defined macrons to mark long vowels ā, ē, ī and ō, and short vowels with grave (`) accents. This is rare nowadays since many people write Nahuatl without any orthographic sign and with the letters /k/, /s/ and /w/, not present in the original alphabet. Some projects prefer macron-based writing, as in Nahuatl Wikipedia.
Hawaiian. The macron is called kahakō, and it indicates vowel length, which changes meaning and the placement of stress.
Māori. Early writing in Māori did not distinguish vowel length. Some — notably Professor Bruce Biggs[3] — have advocated that double vowels be written to mark long vowel sounds (e.g., Maaori), but he was more concerned that they be marked at all than with the method. The Māori Language Commission (Te Taura Whiri o te Reo Māori) advocates that macrons be used to designate long vowels. The use of the macron is widespread in modern Māori, although sometimes the diaeresis mark is used instead (e.g. "Mäori" instead of "Māori") if the macron is not available for technical reasons [1]. The Māori words for macron are pōtae "hat", or tohuto.
Tongan. Called the toloi, its usage is similar to that in Māori, including its substitution by a diaeresis.
In Pinyin, macrons are used over a, e, i, o, u, ü (ā, ē, ī, ō, ū, ǖ) to indicate the first tone of Mandarin Chinese. The alternative to macron is the number 1 after the syllable, e.g. tā = ta1.
In some German handwriting the a macron is used to distinguish u from n or instead of the umlaut.
In some Finnish and Swedish comic books that are hand-lettered, or in handwriting, the macron is used instead of ä or ö, sometimes known colloquially as a "lazy man's umlaut".
In older handwriting such as the German Kurrentschrift, the macron over an a-e-i-o-u or ä-ö-ü stood for an n, or over an m or an n meant that the letter was doubled. This continued into print in English in the sixteenth century. Over a u at the end of a word, the macron indicated um as a form of scribal abbreviation.
In Russian handwriting, a lowercase Т looks like a lowercase m, and a macron is often used to distinguish it from Ш, which looks like a lowercase w. Some writers also underline the letter ш to reduce ambiguity further.
In music, the tenuto marking resembles the macron.
In Kokota, ḡ is used for the normal /g/ sound, g without macron the voiced velar fricative /ɣ/; an n with macron (n̄) represents the velar nasal /ŋ/, n without macron the normal /n/ sound.[4]
In Unicode, "combining macron" is a combining character with the code U+0304 (in HTML, ̄ or ̄). This is different from the "macron" at U+00AF ¯, from the "modifier letter macron" at U+02C9 ˉ and from the combining overline at U+0305 ̅. There are several precomposed characters; their HTML/Unicode numbers are as in the table below. In LaTeX a macron is created with the command "\=", for example: M\=aori.
The row before the last is the letter Uu with diaeresis (Ü ü) and macron, used in pinyin. The final row is the letter Yy with macron, used sometimes in teaching Old English and Latin.
^ P.G.W. Glare (ed.), Oxford Latin Dictionary (Oxford at the Clarendon Press 1990), p. xxiii: Vowel quantities. Normally only long vowels in a metrically indeterminate position are marked.
^ Годечкият Говор от Михаил Виденов,Издателство на българската академия на науките,София, 1978, p. 19: ...характерни за всички селища от годечкия говор....Подобни случай са характерни и за книжовния език-Ст.Стойков, Увод във фонетиката на българския език , стр. 151.. (Russian)
Los “caracteres especiales” vuelven a dirigir aquí. Para el uso de caracteres especiales en Wikipedia, vea Wikipedia: Caracteres especiales.
A codificación del carácter consiste en a código eso aparea una secuencia de caracteres del dado juego de caracteres (referido a veces como cifre la página) con algo más, tal como una secuencia de natural números, octetos o pulsos eléctricos, para facilitar almacenaje de texto en computadoras y la transmisión del texto a través de redes de telecomunicación. Los ejemplos comunes incluyen Código Morse, que codifica letras del Alfabeto latino como serie de depresiones largas y cortas de a llave del telégrafo; y ASCII, que codifica letras, números, y otros símbolos, como números enteros.
En días anteriores de computar, la introducción de juegos de caracteres cifrados por ejemplo ASCII (1963) y EBCDIC (1964) comenzó el proceso de la estandardización. Las limitaciones de tales sistemas pronto llegaron a ser evidentes, y un número ad hoc los métodos se convirtieron para extenderlos. La necesidad de apoyar múltiplo sistemas de la escritura (Idiomas), incluyendo CJK familia de las escrituras asiáticas del este, ayuda requerida para un número lejos más grande de caracteres y exigido un acercamiento sistemático al carácter que codifica más bien que los acercamientos ad hoc anteriores.
La codificación convencionalmente del juego de caracteres y del carácter era considerada sinónima, pues el mismo estándar especificaría ambos qué caracteres estaban disponibles y cómo debían ser codificados en una corriente de las unidades del código (generalmente con un solo carácter por unidad del código). Por razones históricas, MIME y los sistemas basados en él utilizan el término charset para referir al sistema completo para codificar una secuencia de caracteres en una secuencia de octetos.
Modelo de codificación moderno
Unicode y su estándar paralelo, ISO 10646 Juego de caracteres universal, que juntos constituyen la codificación más moderna del carácter, se rompió lejos de esta idea, y en lugar de otro separó las ideas de qué caracteres están disponibles, su enumeración, cómo se codifican esos números como una serie de “unidades del código” (los números del limitado-tamaño), y finalmente cómo esas unidades se codifican como corriente de los octetos (octetos). La idea detrás de esta descomposición es establecer un sistema universal de los caracteres que se pueden codificar en una variedad de maneras. Describir correctamente este modelo necesita términos más exactos que “juego de caracteres” y el “carácter que codifica”. Los términos usados en el modelo moderno siguen:
A repertorio del carácter es el sistema completo de los caracteres abstractos que un sistema apoya. El repertorio puede ser cerrado, ésa no es ninguna adición se permite sin crear un nuevo estándar (al igual que el caso con el ASCII y la mayor parte de la serie ISO-8859), o puede estar abierto, permitiendo adiciones (al igual que el caso con Unicode y a un grado limitado Páginas del código de Windows). Los caracteres en un repertorio dado reflejan las decisiones que se han tomado sobre cómo dividir sistemas de la escritura en unidades de información lineares. Las variantes básicas del Latino, Griego, y Alfabetos cirílicos, puede ser analizado en letras, dígitos, la puntuación, y algunas caracteres especiales como el espacio, que puede todos ser arreglado en las secuencias lineares simples que se exhiben en la misma orden se leen. Iguale con estos alfabetos sin embargo signos diacríticos plantee una complicación: pueden ser mirados o como parte de un solo carácter que contiene una letra y un signo diacrítico (sabidos en terminología moderna como a precomposed el carácter), o como caracteres separados. El anterior permite un sistema de tramitación lejos más simple de texto pero el último permite cualquier letra/combinación diacrítica que se utilizarán en texto. Otros sistemas de la escritura, tales como árabe y hebreo, se representan con repertorios más complejos del carácter debido a la necesidad de acomodar cosas como el texto bidireccional y glyphs eso se ensambla junto de diversas maneras para diversas situaciones.
A juego de caracteres cifrado especifica cómo representar un repertorio de los caracteres que usan un número de códigos no negativos del número entero llamados puntos de código. Por ejemplo, en un repertorio dado, un carácter que representaba la mayúscula “A” en el alfabeto latino se pudo asignar al número entero 65, el carácter para “B” a 66, y así sucesivamente. Un sistema completo de caracteres y de números enteros correspondientes es un juego de caracteres cifrado. Los juegos de caracteres cifrados múltiples pueden compartir el mismo repertorio; por ejemplo ISO-8859-1 y el código de IBM pagina 037 y 500 todos cubren el mismo repertorio pero traz los a diversos códigos. En un juego de caracteres cifrado, cada punto de código representa solamente un carácter.
A forma de codificación del carácter (CEF) especifica la conversión de los códigos del número entero de un juego de caracteres cifrado en un sistema del número entero del limitado-tamaño valores de código eso facilita almacenaje en un sistema que represente números en forma binaria usando un número fijo de pedacitos (es decir. prácticamente cualquier sistema informático). Por ejemplo, un sistema que almacena la información numérica en 16 unidades del pedacito podría solamente representar directamente números enteros a partir de la 0 a 65.535 en cada unidad, pero números enteros más grandes se podrían representar si más de una unidad de 16 pedacitos podría ser utilizado. Éste es un qué CEF acomoda: define una manera de traz solo código punto de una gama de, por ejemplo, 0 a 1.4 millones, a una serie de uno o más código valores de una gama de, por ejemplo, 0 a 65.535.
El sistema más simple de CEF es simplemente elegir bastante grandes unidades que los valores del juego de caracteres cifrado pueden ser codificados directamente (un punto de código a un valor de código). Esto trabaja bien para los juegos de caracteres cifrados que caben en 8 pedacitos (como lo hacen la mayoría de las codificaciones del non-CJK de la herencia) y para los juegos de caracteres cifrados que para caber razonablemente bien en 16 pedacitos (tales como versiones tempranas de Unicode). Sin embargo, como el tamaño del juego de caracteres cifrado aumenta (e.g. Unicode moderno requiere por lo menos 21 pedacitos/carácter), éste llega a ser cada vez menos eficiente, y es difícil adaptar sistemas existentes para utilizar valores de código más grandes. Por lo tanto, la mayoría de los sistemas que trabajan con versiones más últimas de Unicode utilizan cualquiera UTF-8, que traz puntos de código de Unicode a las secuencias variable-length de octetos, o UTF-16, que traz puntos de código de Unicode a las secuencias variable-length de 16 palabras del pedacito.
Después, a esquema de codificación del carácter (CES) especifica cómo los códigos de tamaño fijo del número entero se deben traz en una secuencia del octeto conveniente para ahorrar en un sistema de ficheros octeto-basado o un excedente que transmite una red octeto-basada. Con Unicode, un esquema de codificación del carácter simple se utiliza en la mayoría de los casos, especificando simplemente si los octetos para cada número entero deben estar en grandeendian o pequeña-endian orden (incluso esto no se necesita con UTF-8). Sin embargo, hay también los esquemas de codificación del carácter compuesto, que utilizan semencias de escape para cambiar entre varios esquemas simples (por ejemplo ISO 2022), y los esquemas de compresión, que intentan reducir al mínimo el número de octetos utilizó por unidad del código (por ejemplo SCSU, BOCU, y Punycode).
Finalmente, puede haber a protocolo de alto nivel cuál provee la información adicional que se puede utilizar para seleccionar la variante particular de a Unicode carácter, particularmente donde hay las variantes regionales que “se han unificado” en Unicode como el mismo carácter. Un ejemplo es el xml de la cualidad de XML: lang.
Windows-1250 para las idiomas centroeuropeas que utilizan la escritura latina, (pulimento, checo, Eslovaco, húngaro, Eslovenia, servio, croata, rumano y albaneses)
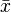 as the average value of
as the average value of 
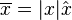 , although boldface and arrows commonly are also used.
, although boldface and arrows commonly are also used.